

16 Jun
¿Alguna vez te has preguntado cómo las inteligencias artificiales pueden responder con tanta precisión a tus preguntas, incluso cuando la información cambia constantemente? La Arquitectura RAG (Retrieval-Augmented Generation) es la clave de este fenómeno revolucionario que está transformando la forma en que interactuamos con la tecnología.
Imagina tener una herramienta que no solo genera respuestas basadas en lo que ya sabe, sino que además se conecta directamente con bases de datos actualizadas para ofrecerte siempre información fresca, exacta y contextualizada.
Suena casi mágico, ¿verdad? Pues esta es precisamente la promesa de la arquitectura RAG: unir lo mejor de dos mundos para crear sistemas mucho más inteligentes y útiles para ti.
Te invito a que sigas conmigo para que, paso a paso, puedas entender y aprovechar todo el potencial que la retrieval-augmented generation tiene para ofrecerte. 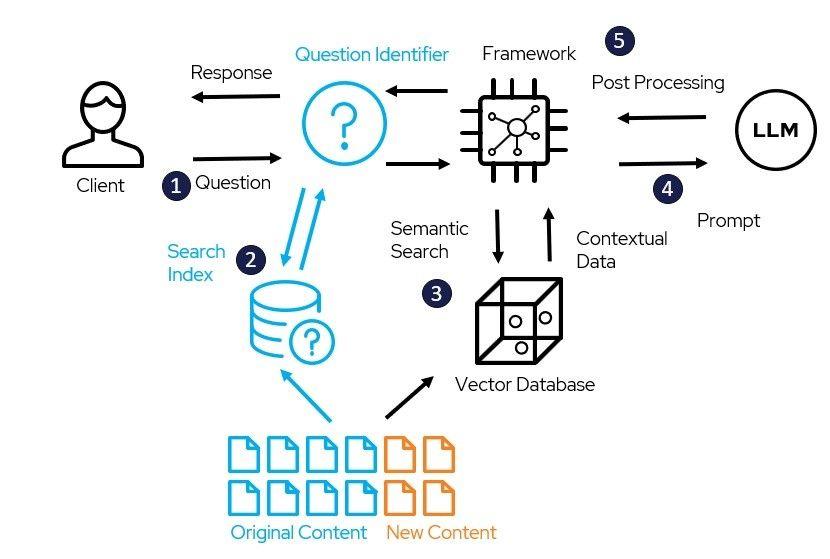
Qué significa realmente la Arquitectura RAG y por qué debería importarte
La Arquitectura RAG (Retrieval-Augmented Generation) representa una revolución silenciosa en cómo las máquinas entienden y responden a tus preguntas.
No es solo otra tecnología de inteligencia artificial; es una estrategia que combina lo mejor de dos mundos: la capacidad de recuperar información relevante de grandes bases de datos y la potencia de los modelos generativos para crear respuestas contextuales, coherentes y precisas.
Piensa en ello como un asistente que no solo recuerda un manual, sino que también sabe explicártelo en tus propias palabras, adaptándose a lo que necesitas en cada interacción.
¿Por qué debería importarte? Porque esta arquitectura rompe con el paradigma tradicional donde los modelos generativos trabajan únicamente con los datos con los que fueron entrenados. En cambio, RAG permite integrar contenido actualizado y específico en tiempo real al proceso de generación.
Imagina que consultas sobre un tema muy concreto y reciente: con RAG, el sistema primero busca fragmentos relevantes en tu base de datos o en la web, y luego utiliza esa información para crear una respuesta precisa, actual y personalizada.
Esto te garantiza información confiable y ultra relevante en cada interacción, algo que cualquier profesional del marketing digital o desarrollo tecnológico valora al máximo.
El proceso detrás de esta arquitectura es fascinante y muy eficiente. Primero, el módulo recuperador escanea documentos, artículos, reportes o cualquier recurso que tengas a disposición, identificando lo que realmente importa para responder a tu consulta.
Luego, el módulo generador toma esos fragmentos y los usa como contexto adicional para modelar respuestas creadas a medida. Esto significa que no hay respuestas genéricas ni texto aleatorio: la conversación se vuelve mucho más útil, práctica y alineada con tus objetivos y demandas específicas.
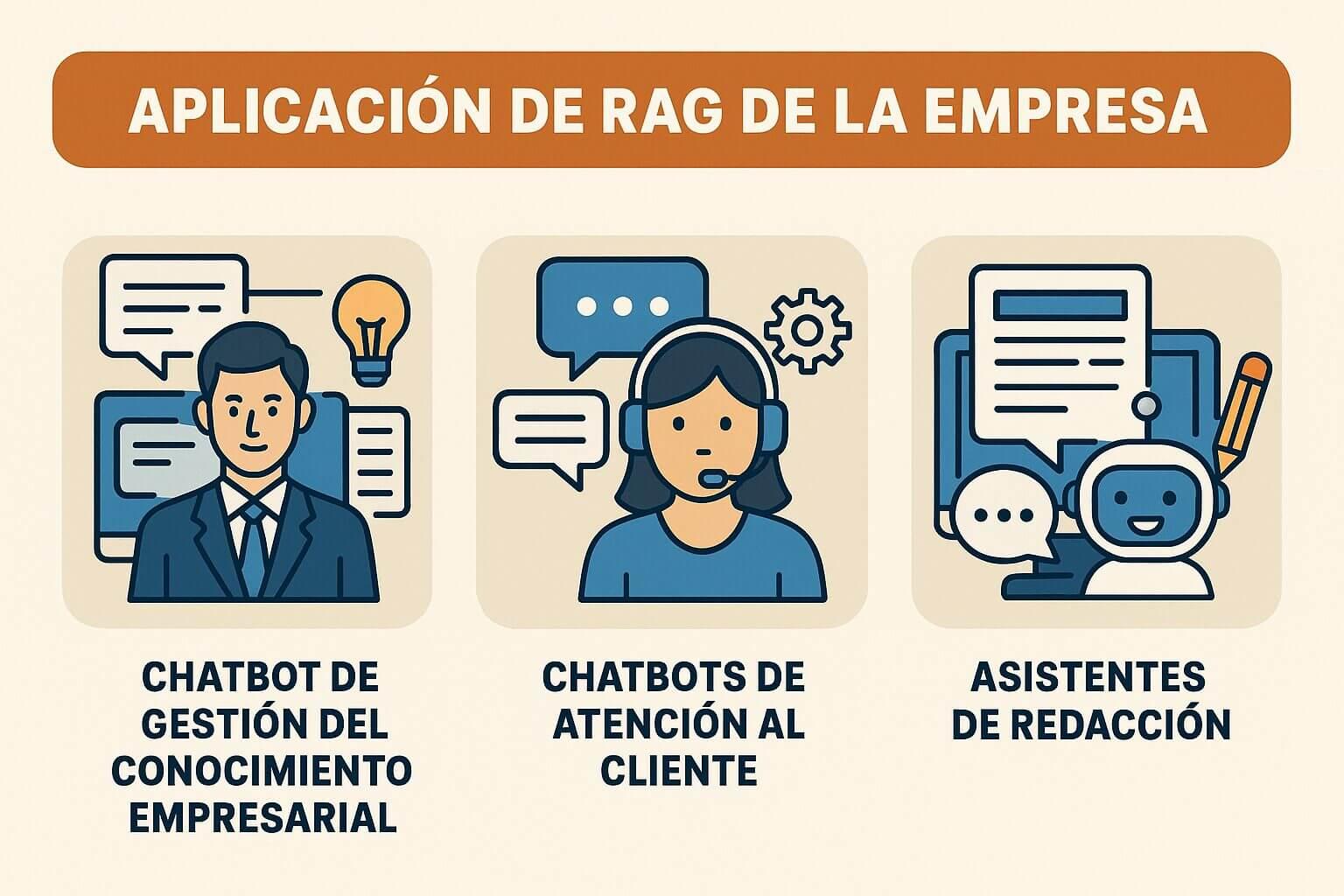
¿Cómo puede transformar tu trabajo o negocio? Aquí está el valor real de RAG: amplía la capacidad de los chatbots, asistentes virtuales y sistemas de atención al cliente para manejar consultas complejas que requieren datos actuales o específicos.
Ya no dependen solo del conocimiento aprendido durante el entrenamiento, sino que se apoyan activamente en bases de datos y sistemas de búsqueda avanzados, como Azure AI Search, para ofrecerte soluciones más inteligentes y personalizadas.
Esto se traduce en mejor experiencia usuario, mayor eficiencia y reducción de errores al tratar con información técnica o voluminosa.
Finalmente, si te preguntas si esta innovación es solo para grandes compañías con recursos ilimitados, la respuesta es no.
La arquitectura RAG está diseñada para ser escalable y adaptable: desde startups hasta agencias de marketing digital pueden integrar este enfoque para potenciar su oferta y destacarse en un mercado que cada vez exige respuestas más rápidas y precisas.
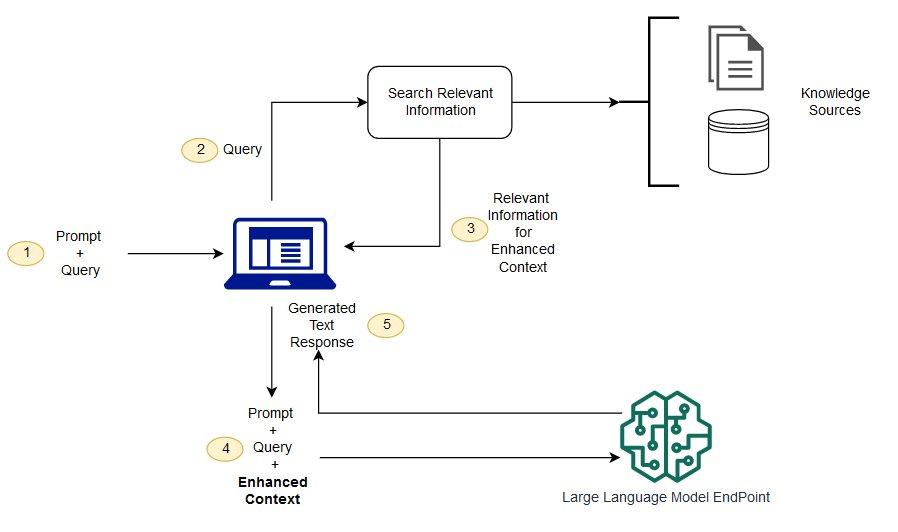
Cómo funciona la magia tras bambalinas del Retrieval-Augmented Generation
Imagina que tienes acceso inmediato a una vasta biblioteca digital repleta de información, pero necesitaras que alguien escanee, seleccione y entregue justo lo que necesitas en el momento preciso.
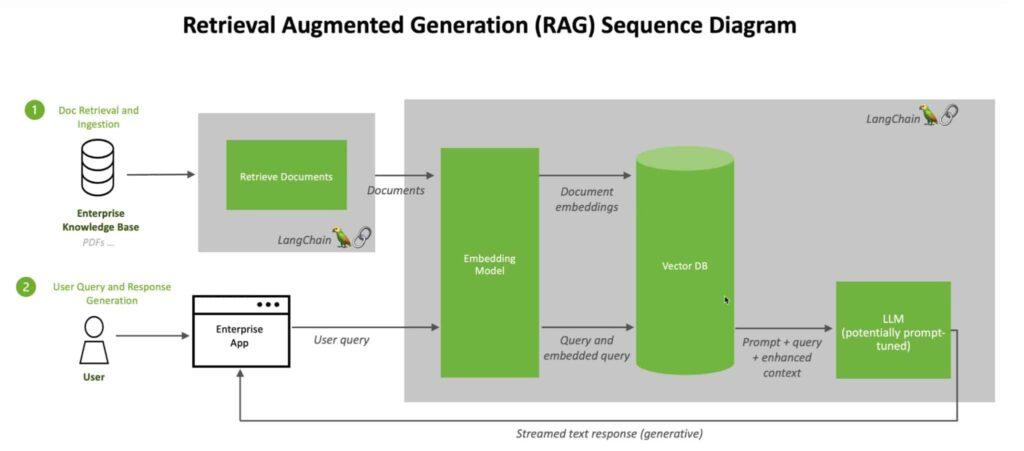
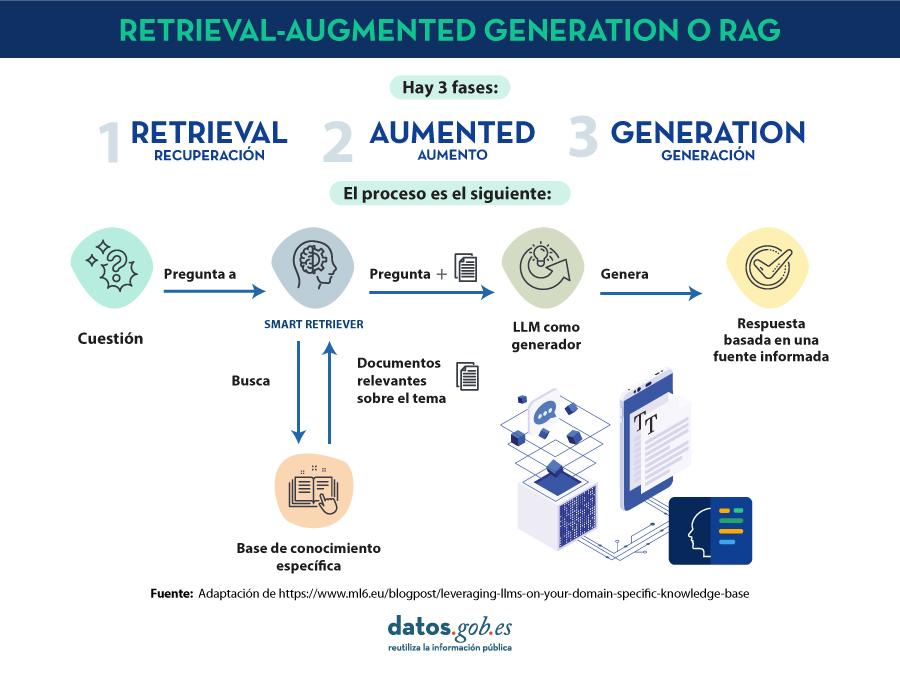
Eso es, en esencia, lo que sucede tras bambalinas en la magia del Retrieval-Augmented Generation (RAG). Esta arquitectura combina lo mejor de dos mundos: la capacidad de recuperar datos relevantes de una base de conocimiento y la brillante habilidad de los grandes modelos de lenguaje para tejer respuestas coherentes y contextuales basadas en esos datos.
Primero, el sistema actúa como un explorador digital, iniciando su trabajo con una recuperación inteligente de información.
Cuando tú le haces una pregunta o planteas una consulta, el componente de recuperación (generalmente un motor de búsqueda vectorial) busca dentro de una gran colección de documentos para encontrar aquellos fragmentos que más se alinean con tu intención.
Esto no es un simple “match” por palabras clave, sino un análisis semántico profundo que entiende el significado detrás de tu texto, garantizando así que solo la información más pertinente atraviese el filtro.
Una vez que los fragmentos relevantes están listos, empiezan las verdaderas “chispas de magia”. El modelo generativo recibe estos contextos recuperados junto con tu consulta original, fusionándolos para dar forma a una respuesta completa y detallada.
Aquí, el poder del aprendizaje profundo cobra vida transformando datos crudos y dispersos en una narrativa fluida, enriquecida y adaptada exactamente a lo que tú buscas.
Es una bendición para ti, puesto que no solo obtienes información cruda, sino una interpretación afinada que te ahorra tiempo y evita distracciones innecesarias.
Debes saber que varios factores influencian qué tan eficaz es esta coreografía entre recuperación y generación. Desde la calidad y actualización de la base de datos hasta la capacidad del modelo para procesar y sintetizar información compleja, cada pieza juega un papel crítico.
Incluso la relevancia semántica y la forma en que se entregan los datos al modelo generativo puede transformar por completo la experiencia, haciendo que la respuesta sea precisa, útil y convincente. Por eso, detrás de escena hay un delicado equilibrio que mantiene el sistema ágil y confiable.
Al optar por esta arquitectura, te beneficias de un poderoso asistente virtual que no solo conoce las respuestas, sino que también sabe dónde encontrarlas y cómo presentarlas mejor para ti.
Esta es la esencia del RAG: una combinación perfecta que convierte un océano de datos fragmentados en respuestas inteligentes y dinámicas, ayudándote a tomar decisiones más rápidas y acertadas. En un mundo donde la velocidad y la precisión marcan la diferencia, esta magia tras bambalinas se convierte en tu mejor aliada digital.
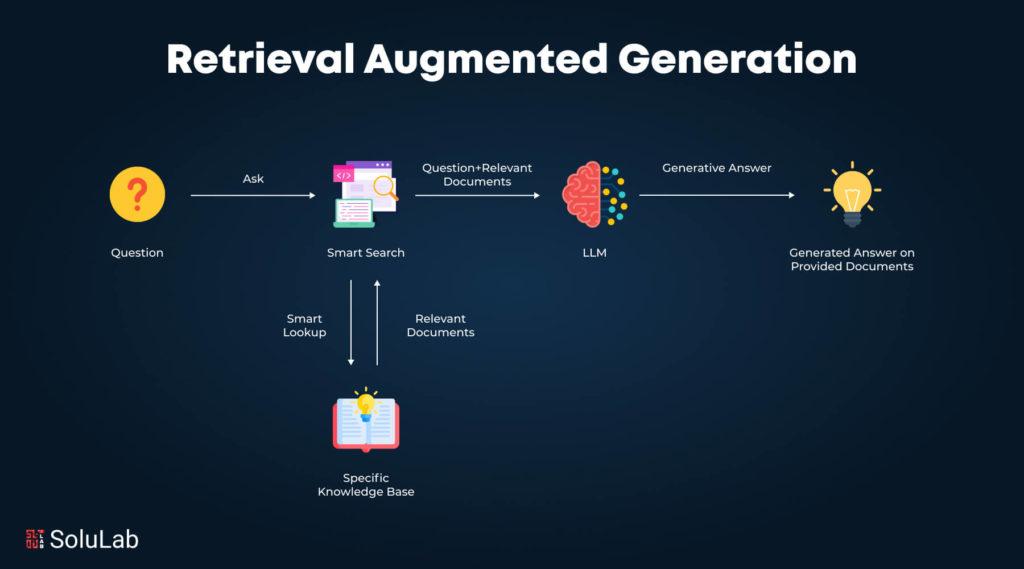
Los componentes clave que hacen única a la arquitectura RAG y cómo trabajan contigo
Cuando te adentras en la arquitectura RAG, descubres una sinergia poderosa entre tres componentes clave que trabajan contigo para transformar la manera en que obtienes información precisa y contextual.
Primero, está el modelo generativo de lenguaje natural (LLM), la base creativa que transforma datos en respuestas humanas, fluidas y naturales. Este modelo ya viene entrenado con un vasto conocimiento, pero aquí no acaba la magia.
El verdadero poder de RAG reside en cómo este modelo interactúa con datos externos en tiempo real, ofreciéndote una experiencia siempre actualizada y relevante para tu consulta.
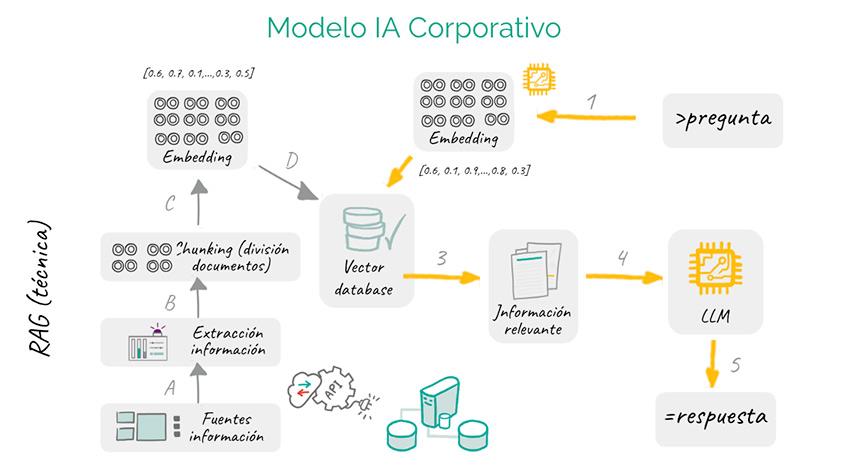
El segundo elemento esencial es el sistema de recuperación de información, que funciona como tu asistente experto buscando en grandes bases de datos o repositorios vectoriales.
Imagina que necesitas respuestas basadas en normativas, precios o cualquier información que cambie constantemente: este componente escanea, filtra y proporciona los fragmentos más relevantes para que el modelo generativo pueda construir respuestas sólidas y ajustadas a la realidad.
Gracias a esta recuperación, no dependes exclusivamente de datos antiguos, ¡tu interacción se renueva constantemente!
Por último, la base de datos vectorial es la joya tecnológica que permite almacenar y gestionar esa información externa de forma eficiente.
Aquí, los datos no solo se guardan, sino que se organizan en un formato que facilita búsquedas rápidas y precisas usando vectores semánticos, lo que significa que el sistema entiende el contexto de lo que buscas, no solo palabras clave.
Tú te beneficias directamente de esta estructura porque encuentras respuestas más inteligentes, ágiles y profundas, sin perder tiempo en búsquedas manuales tediosas.
Cómo trabajan estos componentes contigo
El proceso se traduce en una colaboración sin fricciones: cuando haces una pregunta, el sistema inicia una búsqueda, extrae la información más valiosa y la pasa al modelo generativo para que formule una respuesta completa. No hay necesidad de entrenamientos adicionales frecuentes, ya que el modelo usa su conocimiento previo complementado en tiempo real con datos externos.
Esto te otorga una ventaja insuperable, especialmente en sectores dinámicos como el marketing digital, donde la información fresca y actualizada puede marcar la diferencia en tus estrategias.
Además, esta arquitectura te ofrece flexibilidad para mantener tu base de datos actualizada en segundo plano, de forma asíncrona o programada, sin interrumpir tu flujo de trabajo. Por eso, cada vez que interactúas con el sistema, lo haces con la seguridad de que estás recibiendo contenido relevante y verificado, mejorando la toma de decisiones y la productividad en tus proyectos.
Con RAG, tienes un aliado que no sólo entiende lo que preguntas, sino que también te entrega respuestas adaptadas a un mundo en constante cambio.
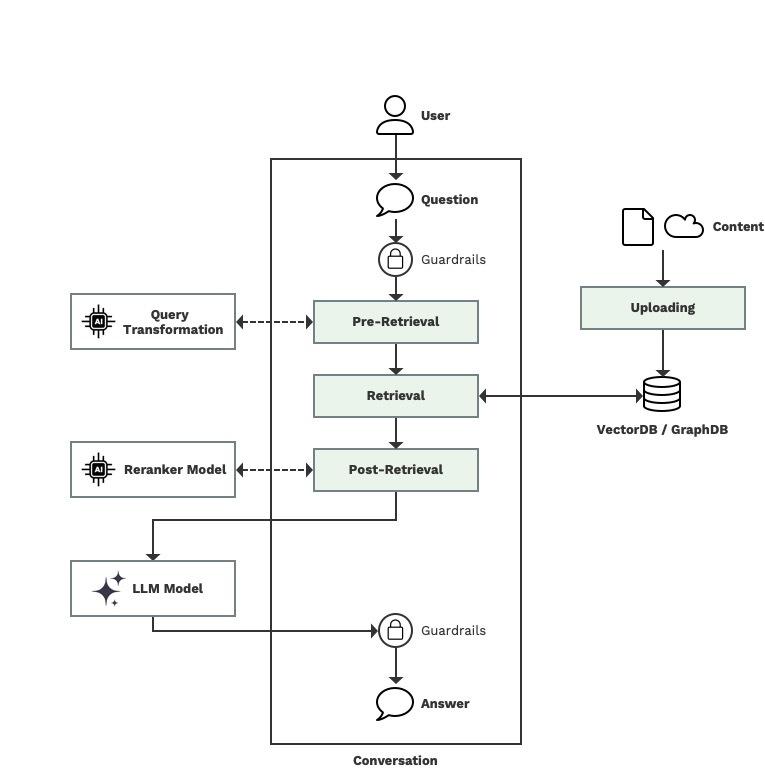
Ventajas concretas que RAG aporta para mejorar tus procesos de generación de contenido
Integrar la arquitectura RAG en tus procesos de generación de contenido te abre la puerta a un nivel de precisión y relevancia que pocos enfoques pueden igualar.
Gracias a la combinación de recuperación y generación, puedes acceder a información actualizada y específica de una base documental o base de datos, lo que garantiza que el contenido que produzcas tenga siempre un respaldo real y verificable.
Esto significa que, en lugar de depender únicamente del conocimiento ingrato y estático de un modelo de lenguaje, contarás con un motor que incorpora datos frescos y contextuales directamente en el texto.
Con RAG, tienes a tu alcance un sistema que reduce drásticamente el riesgo de generar contenido impreciso o desactualizado, algo crucial en sectores donde la información cambia a gran velocidad.
Al incorporar un módulo de recuperación inteligente, puedes enriquecer cada texto con referencias y detalles extraídos de fuentes concretas, logrando así una mayor confianza de tu audiencia y un impacto más significativo en tus campañas de marketing o comunicación.
La eficiencia también es una gran ventaja: RAG automatiza la búsqueda y combinación de datos con la generación de contenido en un solo flujo integrado.
Esto se traduce en menos tiempo invertido en investigación manual y en ediciones posteriores, liberándote para enfocarte en tareas más estratégicas. En un mercado que demanda agilidad y contenido de calidad constante, esta capacidad puede marcar la diferencia para que tu marca nunca pierda ritmo frente a la competencia.
Además, RAG aporta una flexibilidad única a la creación de contenido. Ya no estás limitado a textos genéricos o superficiales; puedes personalizar la generación para distintos públicos, nichos o canales, basándote en los datos que más importan para cada caso.
Esto permite, por ejemplo, generar textos profundos, técnicos o altamente creativos respaldados en documentación precisa, lo que amplía considerablemente el potencial de tu estrategia digital.
Finalmente, esta arquitectura potencia la creatividad y la innovación, al liberarte de ciertas restricciones propias de modelos estándar. Al combinar lo mejor de dos mundos -la recuperación de información y la generación de texto- RAG habilita la creación de contenido que no solo informa, sino que también sorprende y conecta desde una base sólida.
Si buscas optimizar tus procesos, mejorar la calidad y generar contenido con impacto real, implementar RAG es, sin duda, un salto cualitativo que te pondrá un paso adelante en el mundo digital.
Desafíos comunes que puedes enfrentar al implementar RAG y cómo superarlos sin estrés
Implementar la Arquitectura RAG puede parecer una tarea titánica, pero gran parte del estrés surge por retos que, al entenderlos bien, puedes dominar con facilidad. Uno de los desafíos más comunes es la correcta integración entre el sistema de recuperación y el modelo generativo.
Al trabajar con grandes volúmenes de datos, puede que la información recuperada no siempre sea relevante o esté actualizada, lo cual afecta directamente la calidad de las respuestas generadas.
Para evitar esto, es clave diseñar filtros inteligentes y mantener una base de datos bien organizada y constantemente actualizada, asegurando que la información que alimenta tu modelo sea realmente útil y precisa.
Otro punto que puede complicarte la vida es la latencia. Cuando nuestras consultas requieren consumir datos externos o buscar documentos en grandes repositorios, el tiempo de respuesta puede aumentar, afectando la experiencia del usuario final.
Para superar este obstáculo sin quebrarte la cabeza, vale la pena implementar técnicas de caching y optimizar los pipelines de consulta, así como balancear las cargas de trabajo entre servidores. La idea es que tu solución RAG sea rápida y eficiente, sin sacrificar la profundidad ni la precisión del contenido generado.
No menos importante es enfrentarte a la dificultad de mantener la coherencia y la contextualización en las respuestas. RAG combina memorias fragmentadas con capacidad generativa, pero si no manejas adecuadamente cómo se ensamblan esos fragmentos, el resultado puede parecer inconsistente o incluso contradictorio.
Aquí, te ayudará mucho definir reglas claras para la selección de documentos y afinar los prompts que usas para guiar al modelo, favoreciendo así una narrativa fluida y con sentido, que sorprenda a tu audiencia por su naturalidad y precisión.
Cómo desarrollar un flujo robusto y libre de estrés en RAG
Para que la puesta en marcha de tu sistema RAG sea amable con tu tiempo y recursos, te aconsejo tener presentes estos tres pilares:
- Planificación estructurada: Dedica tiempo a mapear las fuentes de datos y a definir criterios claros para su recuperación y procesamiento.
- Monitoreo constante: Implementa indicadores clave que te alerten de cualquier anomalía en la calidad o tiempo de respuesta para intervenir tempranamente.
- Iteración ágil: Optimiza y ajusta tu sistema de forma progresiva, aprendiendo de cada error para estabilizar y mejorar la experiencia del usuario.
Finalmente, el principal consejo para sortear dificultades sin estrés es acompañarte de herramientas y frameworks que faciliten la integración con APIs, la gestión documental y la generación de texto. No tienes que reinventar la rueda; existen recursos que simplifican y robustecen los procesos inherentes a RAG, dejando que tú te enfoques en innovar y potenciar tu producto.
Así, no solo dominas los retos, sino que conviertes la implementación en una experiencia enriquecedora y eficaz.
Herramientas y recursos que necesitas para comenzar a usar RAG hoy mismo
Para que empieces a explotar todo el potencial de la Arquitectura RAG, lo primero que necesitas es contar con un conjunto sólido de herramientas que permitan integrar eficazmente modelos de lenguaje con sistemas de recuperación de información.
Hoy en día, existen plataformas en la nube que facilitan este tipo de implementaciones sin la necesidad de una infraestructura compleja, como los servicios gestionados de OpenAI, Hugging Face o Google Vertex AI.
Estas soluciones te brindan la base para entrenar o ajustar modelos, además del acceso a bancos de datos dinámicos para mejorar la búsqueda contextual.
Un elemento fundamental en RAG es el sistema de backend que maneja la base de datos o el motor de búsqueda que alimenta las consultas. Aquí, la clave está en utilizar motores optimizados para recuperar información relevante en tiempo real, como Elasticsearch, Pinecone, Chroma o Weaviate.
Estas herramientas no solo aceleran la búsqueda sino que también permiten indexar documentos en formatos variados, desde textos hasta PDFs y datos estructurados, facilitando así una búsqueda inteligente y contextualizada que eleva la precisión de las respuestas generadas.
¿Qué software no puede faltar? Además del modelo de lenguaje y el motor de búsqueda, te será imprescindible contar con una plataforma de integración o un framework que orqueste el flujo entre ambos componentes.
Frameworks open-source como LangChain o Haystack son ideales porque simplifican la creación de pipelines dinámicos donde los datos recuperados son procesados y combinados con la generación de texto, y te permiten personalizar cómo se da el paso de la recuperación al lenguaje natural sin complicaciones técnicas excesivas.
Estos recursos abren la puerta a que tú mismo diseñes tu propio asistente inteligente, chatbot o sistema de consulta avanzada.
Otra faceta clave es la gestión y preparación de datos. Trabajar con RAG implica tener una estrategia clara para alimentar tu sistema con contenido preciso y actualizado.
Por eso, herramientas para limpieza y procesamiento de texto, como SpaCy, NLTK o incluso soluciones rápidas con Python, te ayudarán a transformar los documentos en formatos amigables para indexar y buscar.
Además, es crucial que puedas actualizar tu base de datos periódicamente para mantener la relevancia, y aquí los scripts automatizados y APIs juegan un papel determinante para conectar fuentes de datos externas sin perder tiempo ni calidad.
Por último, no olvides la importancia de los recursos educativos y comunidades de soporte que te acompañarán en este camino. Participar en foros especializados, seguir tutoriales y consultar documentación oficial de las herramientas que emplees, serán tus mejores aliados para optimizar la arquitectura y resolver obstáculos.
Involucrarte con comunidades tecnológicas te permitirá estar a la vanguardia y descubrir nuevas integraciones que potencien la experiencia de RAG, haciendo que cada paso que des te acerque más a una implementación exitosa y escalable.
Ajusta y optimiza tu sistema RAG para que responda justo a lo que necesitas
Para que tu sistema RAG realmente marque la diferencia, es fundamental que ajustes y optimices cada componente con especial atención. No se trata solo de integrar datos y lanzar consultas, sino de alinear el motor de recuperación y generación con las necesidades específicas de tu negocio o proyecto.
Piensa en esto como afinar un instrumento musical: un pequeño ajuste puede transformar una melodía regular en una experiencia inolvidable para tu usuario.
El primer paso para lograr esta precisión está en seleccionar y curar un conjunto de datos enriquecidos, representativos y actualizados. Aquí, la calidad es tu mejor aliada: cuanto más relevante y detallada sea la información, más acertadas serán las respuestas generadas.
Ten en cuenta que para aplicar un ajuste fino o fine-tuning a los modelos que forman parte de tu arquitectura RAG, necesitarás un volumen proporcional de datos específicos, pues esto evita resultados genéricos y mejora la especialización en tu dominio.
Optimiza el proceso de recuperación ajustando los parámetros del motor que lee y selecciona la información más pertinente.
Puedes controlar el tamaño y la calidad de las colecciones de documentos, definir filtros semánticos y establecer reglas de indexación para que el sistema sepa priorizar datos críticos antes que información secundaria o irrelevante.
Además, algunos entornos permiten personalizar la lógica de búsqueda para que se adapte a tus preferencias y restricciones de seguridad, garantizando un entorno controlado y eficiente.
Consejos prácticos para ajustar tu sistema RAG
- Segmenta tu contenido en colecciones especializadas: esto facilita que el motor RAG acceda y responda con mayor precisión al contexto requerido.
- Utiliza embeddings personalizados: generan representaciones vectoriales que reflejan mejor las características únicas de tu nicho o industria.
- Implementa pipelines iterativos: donde evaluas continuamente la relevancia y exactitud de las respuestas, ajustando parámetros de búsqueda y generación según el feedback recibido.
Por último, no olvides que la arquitectura RAG es altamente flexible, por lo que puedes experimentar con diferentes combinaciones de ajuste fino y recuperación para encontrar ese balance perfecto entre velocidad, precisión y costo.
Bien trabajada, esta arquitectura potenciará tu capacidad para responder con información fresca y contextualizada, situándote varios pasos adelante en el competitivo mundo del marketing digital y la tecnología.
Si quieres exprimir al máximo el potencial de tu sistema, considera también la integración de métricas automatizadas que te permitan medir el impacto real de tus ajustes sobre la calidad de las respuestas.
Esto facilita una optimización continua y basada en datos, logrando que el RAG no solo responda, sino que aprenda contigo y evolucione para ofrecer soluciones cada vez más personalizadas y acertadas.

Cómo integrar la Arquitectura RAG en tus proyectos sin complicaciones técnicas
Integrar la arquitectura RAG en tus proyectos puede parecer una tarea compleja, pero apostando por un enfoque estructurado y herramientas adecuadas, lograrás una incorporación sencilla y efectiva.
Lo primero que debes hacer es organizar tus datos para optimizar la recuperación. Esto significa preparar tus fuentes de información-documentos, bases de datos, contenido web-normalizándolos y segmentándolos en pasajes relevantes que el sistema pueda consultar rápidamente.
Este paso no solo mejora la velocidad y precisión del modelo, sino que también reduce los costos computacionales al evitar búsquedas innecesarias.
Una vez que tengas tus datos listos, la clave está en seleccionar un sistema de recuperación robusto. Puedes usar desde bases de datos con capacidades de búsqueda avanzada hasta motores de búsqueda semánticos que entienden el contexto de tus consultas.
Herramientas públicas y librerías open source te permiten implementar estos módulos sin invertir grandes recursos. Lo ideal es que el retriever se adapte a tu tipo de contenido y volúmenes, garantizando que las consultas se filtren de manera precisa y veloz.
Después llega el momento de integrar el modelo generativo con el componente de recuperación. Aquí es donde la magia de RAG se hace patente: combinar la información recuperada en tiempo real para construir respuestas precisas y con contexto.
Muchas plataformas en la nube ya ofrecen frameworks específicos y experimentadores que facilitan esta conexión. Por ejemplo, el acelerador de experimentos para RAG de Azure o implementaciones en código abierto te guían a través de iteraciones rápidas, donde podrás evaluar, ajustar y mejorar tu sistema sin complicaciones técnicas profundas.
Consejos prácticos para evitar enredos técnicos
Para que esta integración fluya sin contratiempos, es fundamental que establezcas un sistema de evaluación continua que valide la calidad de las respuestas generadas. Así podrás ajustar parámetros del recuperador o puntear el modelo generativo para afinar resultados.
Además, no dudes en apoyarte en herramientas que persistan los experimentos y los resultados, esto ofrece visibilidad clara sobre qué configuración te aporta mejor rendimiento y precisión.
Finalmente, recuerda que la simplicidad en la arquitectura inicial es tu mejor aliada. Empieza con un prototipo sencillo que combine un pequeño conjunto de datos con un modelo base, aprende de los resultados, y luego escala o especializa según las necesidades de tu proyecto.
Integrar RAG no necesita ser un salto gigantesco, sino una evolución progresiva, apoyada en metodologías claras y recursos que cualquiera puede dominar para potenciar la experiencia de usuario y la innovación en tus aplicaciones.
Consejos prácticos para mantener y escalar tu modelo RAG conforme crecen tus demandas
Para mantener y escalar tu modelo RAG con éxito conforme crecen tus demandas, el primer consejo es que nunca pierdas de vista la calidad del conjunto de datos que alimenta tu sistema de recuperación.
La riqueza y relevancia de las fuentes que seleccionas será la columna vertebral para que el modelo proporcione respuestas precisas y oportunas. Actualizar periódicamente esos repositorios de conocimiento y eliminar información obsoleta o redundante hará que tu RAG mantenga su eficacia incluso cuando el volumen de consultas aumente.
Otro aspecto clave es implementar un sistema de evaluación continua. No te conformes con un rendimiento aceptable: analiza cómo responde tu modelo ante diferentes tipos de preguntas y casos de uso, y ajusta los parámetros en consecuencia.
Combina métricas automáticas con revisiones humanas para detectar patrones de fallo o áreas de mejora. Además, usa la capacidad del modelo para reinterpretar o resumir consultas, ayudando a clarificar intenciones antes de ejecutar la recuperación, lo que mejora la precisión y optimiza el tiempo de respuesta.
Optimización progresiva del pipeline de recuperación
Conforme escalas la arquitectura RAG, es indispensable que optimices el flujo de trabajo. Esto implica implementar mecanismos inteligentes para priorizar qué documentos deben ser consultados primero y limitar la consulta a bases de datos más especializadas según el contexto.
Utilizar técnicas de indexación avanzada y almacenamiento en caché puede reducir la latencia considerablemente, permitiéndote ofrecer una experiencia de usuario ágil incluso bajo una carga elevada.
No olvides que el escalamiento también trae consigo desafíos ligados al costo computacional y la gestión de recursos. Aquí, la clave está en el equilibrio entre performance y economía.
Implementa estrategias de escalabilidad automática que ajusten la potencia de cómputo conforme al tráfico y utiliza modelos de lenguaje ajustados para tareas específicas en lugar de un modelo monolítico. Así, podrás minimizar el gasto sin sacrificar la calidad del servicio.
Finalmente, mantén una cultura de innovación constante. La tecnología RAG está en plena evolución, y las mejoras en técnicas de recuperación, integración de fuentes externas y arquitecturas híbridas son oportunidades que no puedes dejar pasar.
Experimenta con diferentes configuraciones, añade nuevos tipos de datos y aprovecha el feedback directo de tus usuarios para refinar tu modelo. Con una atención continua y una visión abierta, tu sistema RAG podrá crecer contigo y superar cualquier reto que aparezca.
El futuro de Retrieval-Augmented Generation y cómo puedes estar un paso adelante con ella
El futuro de la arquitectura RAG se perfila como una revolución constante en la forma en que los modelos de lenguaje grande interactúan con la información externa.
Imagina un escenario donde la generación de texto ya no se limite a un conjunto fijo de datos entrenados, sino que pueda explorar bases de conocimiento globales en tiempo real.
Esto no solo mejora la precisión, sino que además abre la puerta a aplicaciones personalizadas y altamente dinámicas, donde la información se actualiza y adapta según el contexto y las necesidades particulares de cada usuario, tú incluido.
Para estar un paso adelante, es fundamental que te familiarices con la integración de RAG no solo como una tecnología, sino como una ventaja estratégica en tus proyectos. La capacidad de incorporar búsquedas inteligentes y recuperación de datos certificados te da un poder de diferenciación brutal frente a competidores que solo usan modelos tradicionales.
Piensa en RAG como el motor que transforma un asistente virtual común en un consultor experto que sabe dónde encontrar la información más precisa y pertinente, hasta el último momento, asegurando que cada respuesta que ofrezcas sea confiable y respaldada.
Cómo aprovechar RAG para potenciar tu negocio o proyecto
Quizá ya estés preguntándote: ¿qué pasos concretos puedo dar ahora para no quedarme atrás? Aquí te lanzo algunas ideas que acelerarán tu dominio sobre esta tecnología:
- Capacitación continua: Mantente al día con cursos y guías especializadas que desglosen la evolución de RAG y sus implementaciones prácticas.
- Experimentación temprana: Incorpora modelos RAG en pequeñas pruebas de concepto para medir cuánto mejora la calidad y veracidad de la información generada.
- Colaboración multidisciplinaria: Trabaja junto a equipos de datos, marketing y producto para diseñar soluciones que aprovechen la actualización constante de la base de conocimiento.
- Personalización de fuentes: Configura y selecciona bases de datos o repositorios internos para que el sistema pueda recuperar información que realmente aporte valor y diferencie tu oferta.
El crecimiento del RAG estará acompañado por mejoras tecnológicas en los métodos de recuperación y generación, así como en marcos de evaluación que aseguren su eficiencia y transparencia.
Esto significa que los modelos no solo serán mejores contando historias, sino que podrán justificar y explicar sus elecciones con referencias precisas, generando mayor confianza en ti y en quienes interactúan con tus sistemas.
Finalmente, piensa en RAG como una oportunidad para crear experiencias más humanas y precisas en el entorno digital.
La personalización basada en datos reales y actuales te coloca en la vanguardia, ofreciéndote la capacidad de responder con rapidez y solidez, lo que puede transformar desde campañas de marketing hasta la atención al cliente o la creación de contenido automatizado.
Si decides tomar la iniciativa ahora, no solo estarás aprovechando la innovación tecnológica, sino también construyendo un futuro sostenible para tus proyectos, donde cada interacción se sienta auténtica y confiable.

